XML and Java Tutorial, Part 1
![]()
- About the tutorial
- About developerlife.com
- Before you begin
- Short Introduction to XML
- Using a Java XML Parser to parse XML
- Using the Swing API with XML
- Using the Servlet API with XML
- Downloading the source code and running the programs
- References
About the tutorial #
In this tutorial, we will create an XML document, the contents of which can be accessed using a JFC/Swing application and from a web browser (via a Servlet). The XML document is a very simplistic representation of an address book which stores the name, email and company name of people. The XML document is written manually, and its structure is known by the Swing application and the Servlet.
This tutorial shows how Java can be used to display information in XML documents using a graphical Swing interface and an HTML based interface.
This tutorial demonstrates the simple power of XML, the information is the most important element of the equation. Information rendering engines (user interfaces) can be swapped out as is appropriate for the display device. All these rendering engines all work on the same XML document. Also, XML Parsers from different vendors can be used without making any major changes to the source code, which is another feature of using a standards based information storage format.
About developerlife.com #
The applications created in this tutorial are very simple, too simple for any use in the real world. Part 2 and Part 3 of the tutorial will introduce more real world examples. developerlife hosts tutorials on lots of XML technologies – SAX, DOM, Using Java to manipulate XML, database access using XML, parsing XML from web services, etc. You can find them all here. We have tutorials on Swing and graphics programming, multithreading in Java, as well as SOA related topics, JavaME/J2ME, and GWT content as well.
Before you begin #
While you are reading the tutorial and trying out the examples, please use the links in the references section to understand terms that you are unfamiliar with. I am assuming that you are familiar with XML (and all its related terminology) before you start this tutorial.
Short Introduction to XML #
What is XML? #
XML is described very well in the following tutorial – “What is XML? An introduction”. XML uses markup tags as well, but, unlike HTML, XML tags describe the content, rather than the presentation of that content. By avoiding formatting tags in the data, but marking the meaning of the data itself with custom user definable tags, we actually make it easier to search various documents for a tag and view documents tailored to the preferences of the user. Using XML tags to define what your data means using the natural vocabulary of your data’s domain is the key motivation for XML’s invention and the basis of its usefulness. XML data can be rendered differently, depending on the destination device. The XML processor can exist on the server, the client, or both.
What is DOM? #
This tutorial explains what Document Object Model (DOM) is – “Introduction to DOM 1.0 API”. DOM is a set of platform and language neutral interfaces that allow programs to access and modify the content and structure of XML documents. This specification defines a minimal set of interfaces for accessing and manipulating XML document objects. The Document Object Model is language neutral and platform independent. A DOM object is used to extract information from an XML document in a Java program (using a Java XML Parser). You can learn more about DOM in the Java and XML book.
Using a Java XML Parser to parse XML #
You first need a well formed XML document and a validating XML parser in order to read information into your programs. JDOM is a good parser to use Java – you can download it here. You can use SAX to retrieve information from XML documents as well, but SAX is not used in this tutorial.
How to create a DOM object from an XML document #
Java interfaces for DOM have been defined by the W3C and these are available in the org.w3c.dom package. The code that is required to instantiate a DOM object is different depending on which parser you use. Details on instantiating DOM objects using JDOM are provided here. You can learn more about JDOM in the Java and XML book.
You must have the a String URL of the XML document before you can instantiate a DOM object from it. Assume that an XML file called AddressBook.xml is at the following URL. Here is the code to create a DOM object from this URL:
import org.jdom.JDOMException;
import org.jdom.input.SAXBuilder;
import java.io.IOException;
try{
SAXBuilder parser = new SAXBuilder();
Document doc = parser.build(
"http//developerlife.com/xmljavatutorial1/AddressBook.xml");
// work with the document...
}catch(Exception e){}
How to use DOM to extract information from XML documents
Now that the DOM (org.w3c.dom.Document) object has been creating using either parser, it is time to extract information from the document. Lets talk about the AddressBook.xml file. Here is the DTD for this XML file:
<?xml version="1.0??>
<!DOCTYPE ADDRESSBOOK [
<!ELEMENT ADDRESSBOOK (PERSON)*>
<!ELEMENT PERSON (LASTNAME, FIRSTNAME, COMPANY, EMAIL)>
<!ELEMENT LASTNAME (#PCDATA)>
<!ELEMENT FIRSTNAME (#PCDATA)>
<!ELEMENT COMPANY (#PCDATA)>
<!ELEMENT EMAIL (#PCDATA)>
]>
Here is an illustration of this DTD:
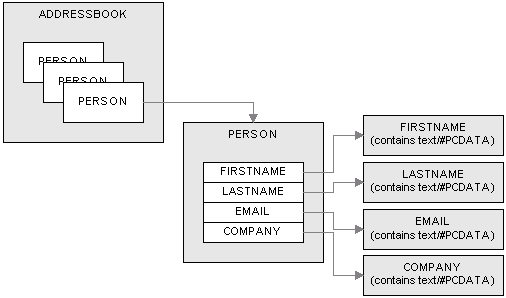
DOM creates a tree based (or hierarchical) object model from the XML document. The Document (created from an XML file) contains a tree of Nodes. Methods in the Node interface allow you to find out whether a Node has children or not, and also what the type of the Node is and what its value is (if any). There are many types of Nodes, but we are interested in the following types: TEXT_NODE (=3), ELEMENT_NODE(=1). These types are static int values which are defined in the org.w3c.dom.Node.java interface created by the W3C. So a Document object is a simple container of Nodes. But, in our DTD, we have Elements, not Nodes. It just so happens that there is an interface called Element (which extends Node). It also turns out that a Node which is of type ELEMENT_NODE is also an Element. Nodes of type ELEMENT_NODE (or Elements) can also have children. How do you access these children? Through the NodeList interface of course; the NodeList interface defines 2 methods to allow the iteration of a list of Nodes. These NodeList objects are generated by Node objects of type ELEMENT_NODE (or Element objects). The Document interface has a method called getElementsByTagName(String tagname ) which returns a NodeList of all the Elements with that tag name.
So here is how we can extract information from our Document object. We first ask the document object for all the Element objects that have the tag name “PERSON”. This should return all the Element objects that are PERSONs; all the Element objects with this tag name are returned in a NodeList object. We can use the getLength() method on this NodeList to determine how many PERSON elements are in the NodeList. Here is some code to do this:
Document doc = ... //create DOM from AddressBook.xml
NodeList listOfPersons = doc.getElementsByTagName( "PERSON" );
int numberOfPersons = listOfPersons.getLength();
Now that we have the NodeList object containing all the PERSON Elements (which are also Nodes), we can iterate it to extract information from each PERSON Element (Node). The method item(int index) in NodeList returns a Node object. Remember that when the type of a Node is ELEMENT_TYPE, it is actually an Element. So here is the code to get the first person from our NodeList (assuming there is at least one person in the AddressBook.xml file):
if (numberOfPersons > 0 ){
Node firstPersonNode = listOfPersons.item( 0 );
if( firstPersonNode.getNodeType() == Node.ELEMENT_NODE ){
Element firstPersonElement = (Element)firstPersonNode;
}
}
Now we have a reference to the firstPersonElement, which we can use to find out the FIRSTNAME, LASTNAME, COMPANY and EMAIL information of this PERSON element. Since the firstPersonElement is an Element, we can use getElementsByTagName(String) again to get the FIRSTNAME, LASTNAME, COMPANY and EMAIL elements in it. Here is the code to do get the FIRSTNAME element of the firstPersonElement:
NodeList firstNameList =
firstPersonElement.getElementsByTagName( "FIRSTNAME" );
Element firstNameElement =
firstNameList.item( 0 );
The firstNameElement contains a list of TEXT_NODEs (one of which is the value of the first name of this person). So the firstNameElement must be asked to return a list of TEXT_NODEs that it contains (in order to get the text which is the first name of this person). Here is the code to get a list of TEXT_NODEs contained in this firstNameElement:
NodeList list = firstNameElement.getChildNodes();
Along with the text (which is the first name of the person), this NodeList (list) may contain other Nodes (of type TEXT_NODE); this text is useless to us, because it consists of whitespace and carriage return and line feeds (crlf). This is NOT intuitive, because we expect only the name of the person to be in the NodeList, instead there are a bunch of nodes in this NodeList which contain a whitespace, crlfs and the String that we really want. So how do we extract the first name from this mess? We have to iterate the NodeList, and ask each Node in it for its value by using the getNodeValue() method. Then we have to trim() the String value and make sure that it is not “” or “\r”. When we have found a value that is not whitespace or crlf, then we can assume that it is the first name of the person. Here is the code to do this parsing:
String firstName = null;
for (int i = 0 ; i < list.getLength() ; i ++ ){
String value =
((Node)list.item( i )).getNodeValue().trim();
if( value.equals("") || value.equals("\r") ){
continue; //keep iterating
}
else{
firstName = value;
break; //found the firstName!
}
}
Now, this procedure must be repeated on firstPersonElement for the LASTNAME, COMPANY and EMAIL elements. You might consider putting this parsing of the NodeList to get a text value in a utility method (in an XML utility class that you can write).
The diagram below presents a visual representation of all the code that we have gone over so far to get information out of a Document:

This was the hard part, integrating this information with a TableModel and making it available to a Servlet is relatively easy!
Using the Swing API with XML #
In order to render information in an XML document to a Swing JComponent, it is necessary to build a custom model which accesses the underlying information in a Document. It is important to remember that in Swing, the models are interfaces which allow access to the underlying data, they dont have to contain the data themselves. This is why all the models are Java interfaces, like TableModel, TreeModel and ListModel.
In this tutorial, we will create a custom TreeModel around the AddressBook.xml and then display the data in a JTable. This information will not be editable right now (that’s in the next part of the tutorial). You can learn more about Swing tables in the Java Swing book.
How to make Swing models wrap around DOM objects
The first step is to create the XML file, then write some code to create a Document object and parse it to get information out of it. Then, a custom TableModel must be created around this code, to allow a JTable access this information. Below is a partial listing of AddressBookMode.java class which implements the TableModel interface and allows access to data in the AddressBook.xml file:
public class AddressBookModel implements TableModel{
...
//CONSTANTS
public static final String URL =
"http//beanfactory.com/xml/AddressBook.xml";
//TABLE META DATA
public static final String ROOT_ELEMENT_TAG = "PERSON";
public static final String[] colNames ={
"LASTNAME",
"FIRSTNAME",
"COMPANY",
"EMAIL"
};
...
//DATA
protected Document doc;
...
//TableModel Implementation
/**
Return the number of persons in an XML document
*/
public int getRowCount() {
return XmlUtils.getSize( doc , ROOT_ELEMENT_TAG );
}
/**
Return the value of text at the specified r (row) and
c (col) location in the table. The row and col information
is translated in the Document, to get the rth person from
the Document, and then get the element value of the tag
that by the name of colNames[ c ]. This is the main "trick"
in this entire class.
*/
public Object getValueAt(int r, int c) {
//must get row first
Element row =
XmlUtils.getElement( doc , ROOT_ELEMENT_TAG , r );
//must get value for column in this row
return XmlUtils.getValue( row , colNames[c] );
}
The two interesting methods in this TableModel are shown above. Note that a static String array is used to hold all the column names for this TableModel, which just happen to be the names of the Elements in a PERSON Element. This is by design, since the structure of the AddressBook.xml document is basically a 2 dimensional array, with rows and columns. The column names are known already since we made the DTD. This is why all the column names are stored in a static array called colNames. In order to access each cell in the TableModel a row and column identifier is needed. But, information in the Document is not stored by rows and columns, so we have to write a simple translation code. Every row in the TableModel is actually a PERSON Element in the Document. Now, every PERSON element has a FIRSTNAME, LASTNAME, COMPANY and EMAIL information, which is represented by the column identifier for the given row (or PERSON). In the getValue( int r, int c ) method above, this trick is used to information from the Document. Notice that before accessing Elements inside a PERSON, the column integer is converted to a column name (by using the colNames[]). The XmlUtils.java class is very simple and is written to work only for this example, you can write a generic one for different types of data, 1D array, 2D array, etc.
Here is a partial listing of the XmlUtils.java class:
public class XmlUtils{
...
/**
Return an Element given a Document, tag name, and index
*/
public static Element getElement(Document doc , String tagName , int index ){
//given an XML document and a tag
//return an Element at a given index
NodeList rows =
doc.getDocumentElement().getElementsByTagName(tagName);
return (Element)rows.item( index );
}
/**
Return the number of person in the Document
*/
public static int getSize( Document doc , String tagName ){
NodeList rows =
doc.getDocumentElement().getElementsByTagName(
tagName );
return rows.getLength();
}
/**
Given a person element, must get the element specified
by the tagName, then must traverse that Node to get the
value.
Step1) get Element of name tagName from e
Step2) cast element to Node and then traverse it for its
non-whitespace, cr/lf value.
Step3) return it!
NOTE Element is a subclass of Node
@param e an Element
@param tagName a tag name
@return s the value of a Node
*/
public static String getValue( Element e , String tagName ){
try{
//get node lists of a tag name from a Element
NodeList elements = e.getElementsByTagName( tagName );
Node node = elements.item( 0 );
NodeList nodes = node.getChildNodes();
//find a value whose value is non-whitespace
String s;
for( int i=0; i<nodes.getLength(); i++){
s = ((Node)nodes.item( i )).getNodeValue().trim();
if(s.equals("") || s.equals("\r")) {
continue;
}
else return s;
}
}
catch(Exception ex){}
return null;
}
...
}//end class
The getElement() method is very straighforward, it is used to get the PERSON Element in the row index of the TableModel. Once you have a PERSON Element, you need to extract information from its column indexes. This is where the getValue() method comes in. Given a PERSON Element, it translates column names into values for that column.
That’s it! You now know how to extract information from XML Documents and present them in Swing components. In the source code provided, you have to run the AddressBookFrame class in order to see the JTable with the XML information in it. You must also be connected to the Internet at the time, since the AddressBook.xml file is downloaded from the beanfactory.com webserver. If you are not connected to the Internet at the time your run this program, it will appear to hangup (it waits for an Internet connection to be made).
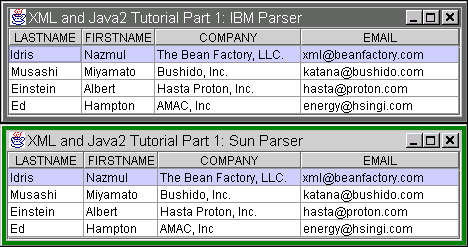
Here are two screen shots of the AddressBookFrame class in action, one for the Sun parser and one for the IBM parser:
Using the Servlet API with XML #
Displaying this XML Document using a Servlet is very similar to creating a TableModel around it. The init() method of the Servlet can create a Document object from an XML file. Then the doGet() method simply has to extract all the values for every column of every row in the Document (using the XmlUtil class) and display a HTML table from it. You can learn more about Servlets in the Java Servlet Programming book.
How to make XML information available to the Web
The following is a listing of the AddressBookServlet.java (for the IBM Parser) which displays this information to a browser. Most of the code here generates the HTML. The actual Document parsing is the same as in the TableModel.
public class AddressBookServlet extends HttpServlet {
//CONSTANTS
public static final String
URL = "http//beanfactory.com/xml/AddressBook.xml";
public static final String ROOT_ELEMENT_TAG = "PERSON";
public static final String[] colNames ={
"LASTNAME",
"FIRSTNAME",
"COMPANY",
"EMAIL"
};
//DATA
protected Document doc;
/**
When this method receives a request from a browser, it
returns a Document in table format.
@param req http servlet request
@param res http servlet response
@exception ServletException
@exception IOException
*/
protected void doGet(HttpServletRequest req, HttpServletResponse res)
throws ServletException, IOException {
res.setContentType("text/html");
PrintWriter out = new PrintWriter(res.getOutputStream());
out.print( "<html>" );
out.print( "<title>" );
out.print( "XML and Java2 Tutorial Part IBM Parser" );
out.print( "</title>" );
out.print( "<center>" );
out.print( "<head><pre>" );
out.print( "http//beanfactory.com/xml/AddressBook.xml" );
out.print( "</pre></head><hr>" );
//format the table
out.print( "<table BORDER=0 CELLSPACING=2 " );
out.print( "CELLPADDING=10 BGCOLOR=\"#CFCFFF\" >" );
out.print( "<tr>");
//display table column
for(int i=0; i<colNames.length; i++){
out.print( "<td><b><center>" +
colNames[i] +
"</center></b></td>" );
}
out.print( "</tr>" );
//need to iterate the doc to get the fields in it
int rowCount = XmlUtils.getSize( doc , ROOT_ELEMENT_TAG );
for(int r=0; r<rowCount; r++) {
out.print( "<tr>" );
Element row = XmlUtils.getElement(
doc , ROOT_ELEMENT_TAG , r );
int colCount = colNames.length;
for(int c=0; c < colCount; c++) {
out.print( "<td>" );
out.print( XmlUtils.getValue( row , colNames[c] ));
out.print( "</td>" );
}//end for c=0...
out.print( "</tr>" );
}//end for r=0...
out.print( "</table>" );
out.print( "<hr>Copyright The Bean Factory, LLC." );
out.print( " 1998-1999. All Rights Reserved.");
out.print( "</center>" );
out.println("</body>");
out.println("</html>");
out.flush();
out.close();
}//end method
/**
Create a DOM from an XML document when the servlet starts up.
@param config servlet configuration
@exception ServletException
*/
public void init(ServletConfig config ) throws ServletException{
super.init( config );
//load the Document
try{
//create xml document
URL u = new URL(URL);
InputStream i = u.openStream();
Parser p = new Parser("myParser");
doc = p.readStream(i);
}catch(Exception e){
System.out.println( e );
}
}
/**
Return servlet information
@return message about this servlet
*/
public String getServletInfo(){
return "Copyright The Bean Factory, LLC. 1998." +
"All Rights Reserved.";
}
}//end class
To run this servlet, place the AddressBookServlet.class and XmlUtils.class in the servlet class folder of your servlet engine and access AddressBookServlet using a web browser.
Downloading the source code and running the programs #
The same sets of Java classes are provided for the Sun Parser and IBM Parser. Here is a description of these source code files:
- AddressBookMode.java - Contains the TableModel
- XmlUtils.java - Needed by AddressBookModel.java and AddressBookServlet.java
- AddressBookServlet.java - Contains the servlet
- AddressBookFrame.java - Displays a JTable in a JFrame
- AddressBookPanel.java - Needed by AddressBookFrame.java
To run the Swing JTable program, you can type “java AddressBookFrame” at the command prompt. Make sure that you have Java2 (or JDK1.2) installed on your machine because it will not work with JDK1.1. Also, please make sure that you are connected to the Internet at the time because the programs need to access AddressBook.xml from the website.
To run the Servlet, place the AddressBookServlet.class and XmlUtils.class in your servlet folder, and start your servlet engine. You can access the Servlet from your web browser by using a URL like eg: http://localhost/servlet/AddressBookServlet.
Here is older code using an old Sun parser – sun.zip (it should be pretty easy to swap the Sun parser instantiation with the JDOM parser).
I hope you enjoyed this tutorial, I have lots more XML and Java related tutorials on this site.
References #
You can download JDOM here.
Details on instantiating DOM objects using JDOM are provided here. You can learn more about JDOM in the Java and XML book.
This is a good site to learn about Sun’s parser and also about how to do elementary things like use SAX and DOM. It also has a nice glossary of terms. After visiting this site and learning everything on it, the content on developerlife.com (which involves real-world application of this technology) will make more sense 😁.
Extensible Markup Language (XML) 1.0 W3C Recommendation
This is not useful for parsing or generating XML documents with Java. This specification lists all the rules that apply to a well formed XML document. This document is only good for specific rules about the syntax of XML documents.
Document Object Model IDL Documentation
This is very useful for parsing and generating XML documents using Java. All these interfaces are available in Java (for both the Sun and IBM parsers). The documentation for this IDL was used to create the documentation for the IBM and Sun parser’s source code. This documentation is more detailed than the javadoc generated documentation for the Java interfaces in the org.w3c.dom package.
Document Object Model IDL Definitions
This is not useful for parsing or generating XML documents with Java. This specification lists all the rules that apply to a well formed XML document. This document is only good for specific rules about the syntax of XML documents.
XML, Java and the future of the web
Jon Bosak, who is on the chair of the W3C XML Working Group, does a great job of describing what kinds of products and services can be made possible from the union of Java and XML.
SAX 1.0: The Simple API for XML
This is David Megginson’s website documenting the SAX 1.0 API. It is short and to the point. If you want to learn about SAX 1.0 I recommend reading my SAX Tutorial 😁 though .
👀 Watch Rust 🦀 live coding videos on our YouTube Channel.
📦 Install our useful Rust command line apps usingcargo install r3bl-cmdr(they are from the r3bl-open-core project):
- 🐱
giti: run interactive git commands with confidence in your terminal- 🦜
edi: edit Markdown with style in your terminalgiti in action
edi in action