What is XML? An introduction
![]()
- Introduction
- Tagged Data
- Element
- XML document
- Processing Instruction (PI)
- Data Type Definition (DTD)
- Well formed vs. validated
- Miscellaneous
- Further Reading
Introduction #
The first layer of XML contains XML and DTD documents. This tutorial is a brief review of a small part of the W3C XML 1.0 Recommendation which you will need in order to understand what XML is and how to manipulate it programmatically in Java. The XML 1.0 Recommendation is quite large and XML is many things to many people; just because some features are included in the W3C Recommendation does not necessarily mean that you have to use it. XML has many uses other than the ones I will discuss in detail. There are many good books available that only cover the XML 1.0 Recommendation. This book is intended to be for serious Java programmers, so I cover only the parts of XML that are relevant to Java programmers, and I leave out the parts of XML that are relevant to webpage creators, etc.
For a complete coverage of the XML 1.0 Recommendation, I suggest reading “Just XML”, by John Simpson.
Tagged Data #
XML documents are just text files which contain “tagged” textual data. This textual data is surrounded by strings delimited by “”. The strings within the “” are called tags. For each start tag, there must be a corresponding end tag. So if you define a tag such as “”, and you use it to tag someone’s name, you would use it as shown in figure 2.1. The actual XML would look like: Nazmul Idris .
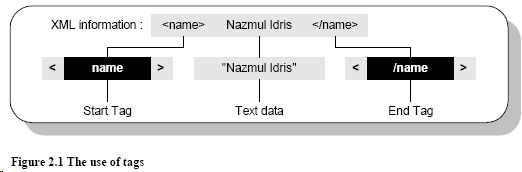
There are no pre-defined tags in XML, and you are free to create any number of tags that you wish. The reason there are no pre-defined tags is that you are the only one who can best describe your data using your own tags. There are a few naming restrictions when using tags:
-
The name of the tag can not contain any spaces.
-
You can have alphanumeric characters (and underscore) in the tag names only, no special characters are allowed.
A simple rule to remember when you name your tags is that you can name your tag anything that you could name a data member/variable in a Java class. XML is also case sensitive, just like Java. So you already know the naming conventions and rules for tags, they are the same as naming variables in Java classes.
The text data, or actual content, of your XML document may have any characters, spaces or numbers in it except the “>” and “” and “ and and < are called entities, you can also define your own entities (which are like constants in Java classes). I will not use entities in this book.
You can also nest tags within each other to create a hierarchical structure of tags. By allowing you to freely create your own tags and nest them in an XML document, XML gives you a lot of power and flexibility to express the structure and content of your data.
Element #
Elements are one of the most important things in XML, I rely almost exclusively on elements in the Java programs written in this book. The element is an encapsulation of the pieces of information listed in table 2.1.

In figure 2.1, the element is called “name”, and its value is “Nazmul Idris”. So you already know what an element is, you just didn’t know it was called an element. In an XML document, you can define the structural relationships between elements (that you create) and also declare the data that is stored in each element. Although an element may have 3 pieces of information in it, it is not required to have all of the pieces of information in it.
XML does not ignore any whitespace characters (empty space, carriage return, line feed) that are part of the value of an element. This is unlike HTML, where the browser simply ignores all whitespace in the data between tags. So when you read in the value of an element, you get all the whitespace characters along with the text that are enclosed between the element’s open and close tags.
XML document #
A simple XML document that stores the names and email addresses of people is shown in figure 2.2. This XML document can have any number of person elements inside it and can be stored in a plain text file.
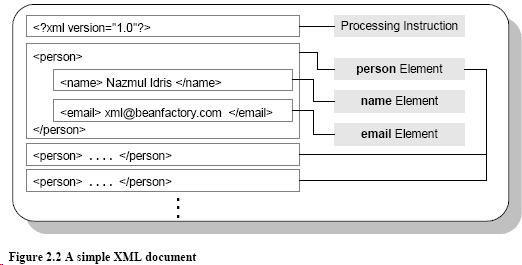
In this document, the person element does not have any data inside it; the following elements are nested inside of it: a name element and email element. So a person element is a container for email and name elements. The name element does contain data, it holds the name of a person. The email element also contains data, it holds the email address of a person. Now you can see how XML documents can store data as well as relationships between the data (or the structure of the data).
Structure vs. data #
There is an important distinction that must be made between the XML’s data storage model (which is plain text) and its ability to define and express the structure that exists in your data. When you nest elements inside another (like name and email elements are nested in a person element), you are defining the structure of your information. This structure does not necessarily store data, but it stores the relationship between elements of your data. Unlike the person element, the name and email elements only store data and no structural relationships.
In Java programming terms, this structure vs. data pattern can be seen when you create classes. Examine the following code for a Person class:
public class Person{
protected String name;
protected String email;
}
By looking at the Person class above, you know that a Person object contains a name and email String object. This expresses the structure of your class, it doesn’t deal with the storage model for Person. However the name and email data members are defined as Strings, this expresses their desired storage model, i.e., name and email are simply String objects. This “class creation” thinking process is similar to what you must use to understand, create and use XML documents.
Processing Instruction (PI) #
Statements in XML like: are called Processing Instructions. You only have to use this one statement to tell the XML Parser what version of the XML Recommendation your document complies with. You simply have to remember to include this one line in every single XML document that you generate, except for DTDs.
Data Type Definition (DTD) #
What is it? #
The XML document shown in figure 2.2 is a standalone document (i.e., it does not have a DTD). DTDs are not required for all XML documents. You can define all the elements which can exist in your XML document, and the relationship between these elements. DTDs add an extra step to creating XML documents: when you use DTDs you must create the DTD first, and create XML documents based on the DTDs next. This is similar to writing a Java class first, and then creating instances of this class (objects), and customizing each object with different data. Without the class definition, the Java Virtual Machine would not know how to deal with objects that belong to that specific class. Similarly, the XML Parser can use the DTD to make sure that the structure of an XML document conforms to its DTD.
So why would you want to use a DTD? The creation of a DTD takes a lot of effort and it really makes you think about what your data looks like, this extra step of rigor generally makes the structure of your XML documents more elegant and useful, it doesn’t allow you to hack out your data or use an incomplete data model. The XML Parser can also use the DTD to make sure that the data in XML documents (that use a specific DTD) conform to the structure defined in the DTD; this feature is not so important for Java programmers who are going to write code to read and write XML, but this feature might be very useful for other applications.
In figure 2.2, I created an XML document that simply stores the names and email address of people. I am going to create an AddressBook DTD, which I can use with the simple XML document I have already created. Here is a listing of this DTD:
<!ELEMENT addressbook (person)*>
<!ELEMENT person (name, email)>
<!ELEMENT name (#PCDATA)>
<!ELEMENT email (#PCDATA)>
This information would be stored in a text file called AddressBook.dtd. This AddressBook DTD defines exactly what the “markup language” is for an Address-Book document. This DTD contains the language for AddressBookML, a custom markup language that I can use to create documents that contain address book data. This is why XML is extensible, you can use it to create your own markup languages! Unlike HTML, where you have to use one markup language for all kinds of data, XML allows you to create your own markup language to describe your own custom data. This is why I defined XML as a language or set of rules that allows you to create your own “language” to describe your information “purely”. XML is what you make out of it. In XML, you are free to create your own markup languages, you can create an HTML DTD if you wish to create valid HTML documents (in fact XML has an HTML DTD).
When I use the AddressBook DTD to create an XML document, this document is called an AddressBookML document; just like when you create a text file that uses valid HTML tags it becomes an HTML document.
In order to use DTDs in the creation of your own XML documents, you must include a URL that points to the location of that DTD file. Here is an example of an AddressBookML document (using the AddressBook DTD):
<?xml version=”1.0”?>
<!DOCTYPE addressbook SYSTEM “file:///z:/somefolder/AddressBook.dtd”>
<addressbook>
<person>
<name> Nazmul Idris </name>
<email> xml@beanfactory.com </email>
</person>
<person>
<name> John Doe </name>
<email> john@doe.com </email>
</person>
</addressbook>
This information would be stored in a file called MyAddressBook.xml. If you wish to use a DTD in your XML document, the only change you have to make is the addition of a reference to the URL to the DTD. The URL can point to a file on your hard drive (as in the example above) or it could point to a file over the web, e.g. “http://developerlife.com/xml/AddressBook.dtd”.
How to create a DTD #
So far I have shown you a simple DTD and a simple XML document that uses it. In this section, I will teach you some very basic and important rules that you have to follow in order to create your own DTDs. There are more rules to create really complex DTDs that I have not covered, but for Java programmers what I cover should suffice.
Root element #
Unlike regular XML documents, DTDs don’t need the PI that tells the parser what version of XML the DTD uses.
The first step in creating a DTD is defining a root element. All DTDs must have at least one root element. This root element is like the root of a tree that may hold many other elements in its leaves and branches. The root element gives all the other elements defined in a DTD a convenient handle to be accessed with. In the Address-Book DTD, the root element name is addressbook.
Element template #
The main content of a DTD is the definition of all the elements that you need and the relationships between these elements (which are all held inside the root element). All elements are defined using the following template: **<!ELEMENT **element-name _( content )>. This template or pattern can be applied recursively to create very complex document structures. The _elementname is just the string that identifies an element, for example, the addressbook, person, name and email elements in AddressBook DTD. The content field can be replaced with any of the things listed in table 2.2.

Modifiers #
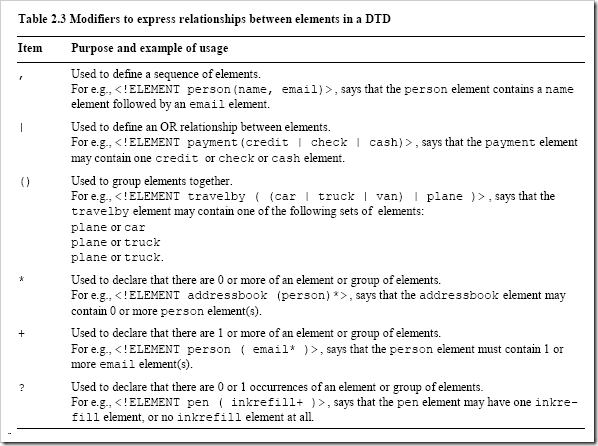
In order to describe rich relationships that exist between the elements in your DTD, XML provides modifiers that allow you to describe these relationships. They are listed in table 2.3. These modifiers can be used on any element that you define in your DTD.
Storage model #
Elements that store data must have a storage model type declared for them. It is important to remember that the actual text data resides in the XML document (that uses a certain DTD). The element definition (in the DTD) merely tells the XML parser how to read the textual information (in the XML document) by specifying a storage model. You will use the #PCDATA storage model almost all the time. This is similar to assigning an instance variable to the String type in Java, e.g.: String myString;. The String defines the type of the myString object. Similarly, in the
DTD you can assign a simple type to your elements (that store some textual data). The available storage models are listed in table 2.4.

Syntax to use a DTD in an XML document #
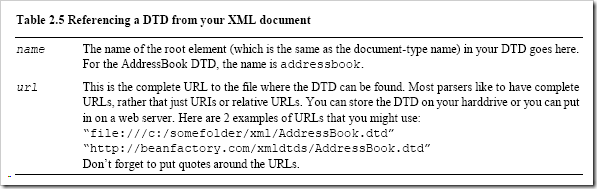
Once you have created a DTD, you have to use it in an XML document. The XML document is the same as before except for one thing, you must reference the external DTD using a tag that looks like:name _**SYSTEM “**_url”>**. You have to replace name and “url” with real values; table 2.5 lists what values these parameters can take. This line must come after the PI (which identifies your document to be XML 1.0 compliant). **
Well formed vs. validated #
XML documents can be well formed and/or validated. If you use a DTD in your XML document, and your XML document conforms to that DTD then it is validated (and well formed). If your XML document does not use a DTD, and it obeys all the rules of creating XML documents (like closing all open tags and using no spaces in tag names) then it is well formed (and not validated). Validated documents are always better because it shows that you are using a DTD. The XML Parser also checks to make sure that the document structure (in your valid XML document) conforms to the DTD you are using. A list of differences between well formed and validated documents is given in table 2.6.

Miscellaneous #
Entity #
Entities are like macros in C and constants in Java. They are placeholders for some real value, which is used when the document is parsed. For example, in HTML you cant use the “>” or “<” characters in your text information, but you can use . The browser knows to replace these pre-defined entities with their actual values when the webpage is displayed. In XML you can define your own entities and use them in your data. In order to let the parser replace the entities with their real values, you have to read this data in as #PCDATA.
Attribute #
An element can have many attributes, e.g. Hola . Here language is an attribute of the greeting element. All attributes may be defined in the DTD. Programmatically, everything you can do with attributes, you can do quite easily with elements.
Notation #
Notations are used to allow XML browsers to handle unknown data or file types, like gif and jpeg images. All notations must be defined in the DTD.
Further Reading #
There are lots of articles on how you can do useful things with Java and XML on developerlife.com. These tutorials will show you how to use DOM, SAX, how to use XML with Swing and Servlets, how to interact with databases, and use a combination of SAX and DOM/XOM.
👀 Watch Rust 🦀 live coding videos on our YouTube Channel.
📦 Install our useful Rust command line apps usingcargo install r3bl-cmdr(they are from the r3bl-open-core project):
- 🐱
giti: run interactive git commands with confidence in your terminal- 🦜
edi: edit Markdown with style in your terminalgiti in action
edi in action