Experimenting w/ Fibers in Project Loom preview
![]()

- Introduction
- Overview of the code in this project
- Runtime performance stats
- Building Project Loom JVM
- Running the server on Project Loom JVM using Fibers
- References
Introduction #
Managing concurrent blocking IO w/ threads in the JDK is a great way to throttle performance and throughput for many server side apps.
I was personally affected by this (around 2008) when I built the backend server infrastructure for ScreamingToaster. I put the JVM and MySQL processes on the same machine. And what ended up happening was that even though I used Servlet 3.0 in order to use async servlets (that use non-blocking NIO and that don’t block a dedicated thread for each network connection), the JDBC connection to MySQL was the bottleneck, since there were many threads connection to the database that were just idling due to IO constraints when accessing data from the database which was on a slow disk (not SSD)!
Project Loom would have helped w/ this throughput issue! However, it didn’t exist back then. Project Loom proposes the creation of new lightweight threads inside the JVM that are not peers to OS threads. They are sometimes referred to as green threads (from the old JDK days).
✨ Here are some great resources on Project Loom (as of Dec 2021).
Overview of the code in this project #
The project implements a simple multithreaded server and client. The server simply waits for a connection, and when a client makes a connection, it accepts it, and simply sends a string over to the client. The client simply displays this string. The server also dumps console logs on all kinds of timing information, and so does the client. When you run the server, and then the client, they will spawn 100_000 threads and take a few minutes to complete.
This example is written using BIO (blocking IO), and not NIO. The Project Loom example is only changed by using Fibers. The idea is to showcase how Loom can have a great impact on existing code that does not use NIO. We can of course use NIO today for this example (and Async Servlets which also use NIO) in order to scale this today (w/out using Loom). Here’s an example of a project similar to this written in NIO.
Here’s a fantastic information on why the BIO code is so slow and consumes so much RAM and CPU! Here’s an excerpt from a stackexchange discussion on this:
“Why does this happen?” is kind of easy to answer. Imagine you have two swimming pools, one full and one empty. You want to move all the water from one to the other, and have 4 buckets. The most efficient number of people is 4.
If you have 1-3 people then you’re missing out on using some buckets. If you have 5 or more people, then at least one of those people is stuck waiting for a bucket. Adding more and more people … doesn’t speed up the activity.
So you want to have as many people as can do some work (use a bucket) simultaneously.
A person here is a thread, and a bucket represents whichever execution resource is the bottleneck. Adding more threads doesn’t help if they can’t do anything. Additionally, we should stress that passing a bucket from one person to another is typically slower than a single person just carrying the bucket the same distance. That is, two threads taking turns on a core typically accomplish less work than a single thread running twice as long: this is because of the extra work done to switch between the two threads.
Whether the limiting execution resource (bucket) is a CPU, or a core, or a hyper-threaded instruction pipeline for your purposes depends on which part of the architecture is your limiting factor. Note also we’re assuming the threads are entirely independent. This is only the case if they share no data (and avoid any cache collisions).
As a couple of people have suggested, for I/O the limiting resource might be the number of usefully queueable I/O operations: this could depend on a whole host of hardware and kernel factors, but could easily be much larger than the number of cores. Here, the context switch which is so costly compared to execute-bound code, is pretty cheap compared to I/O bound code. Sadly I think the metaphor will get completely out of control if I try to justify this with buckets.
Note that the optimal behaviour with I/O bound code is typically still to have at most one thread per pipeline/core/CPU. However, you have to write asynchronous or synchronous/non-blocking I/O code, and the relatively small performance improvement won’t always justify the extra complexity.
Runtime performance stats #
The github repo for this project has instructions on how to get this going on your machine.
Normal JVM version #
Here are some performance numbers for this simple project on hardware (w/out using Loom JVM and using BIO (Java blocking IO). With a new Apple 16” MacBook Pro laptop w/ 64GB RAM and 8 core 5GHz Intel CPU:
- With about 10_000 client threads, the entire program can run in about 17 sec, and the server may wait a few ms at most to accept a connection.
- 100_000 client threads connecting to a simple socket server, the JVM experiences some serious performance issues, w/ threads causing the socket server to wait around for a very long time to be able to accept a new socket connection, max of about 22 sec 😱, and not a few ms! The average time to accept a socket connection increased to about 3 ms. And the entire program takes about 5 minutes to run 😨. The server process only consumed about 4.9 % of CPU. BTW, “Grep Console” is a great plugin to monitor output from the client and server println statements.
Project Loom JVM version #
With a similar machine above, the Project Loom JVM version of the Server using Fibers get the following stats.
- With 100_000 clients, the total time it took for the program to complete is 3.9 min (22% less than the BIO JVM version). On the server, the average time to accept a socket dropped to 2.3 ms (23% less). The max time wait time to accept a socket increased to 19 sec (15% less). The server process only consumed about 2.5 % of CPU.
This is clearly very badly needed! NodeJS is so popular for server applications for this reason, despite being single threaded, since it supports non-blocking IO!
Building Project Loom JVM #
On MacOS, make sure to have XCode installed on your system, and make sure that the command line tools are also available. Then you can follow these instructions.
cd ~/github/
hg clone http://hg.openjdk.java.net/loom/loom
cd loom
hg update -r fibers
sh configure
make images
- You might need to install some packages during the process, but
sh configureshould tell you which commands to run. - Here’s more info on this preview release of the Project Loom JVM.
- There’s a great doc to help w/ this in
./doc/building.html
You will find the built JDK here:
cd ~/github/loom/
cd build/*/images/jdk/bin/java -version
./java -version
On my computer, they are here: ~/github/loom/build/macosx-x86_64-server-release/images/jdk/bin
Running the server on Project Loom JVM using Fibers #
Instead of allocating one OS thread per Java thread (current JVM model), Project Loom provides additional schedulers that schedule the multiple lightweight threads on the same OS thread. This approach provides better usage (OS threads are always working and not waiting) and much less context switching.
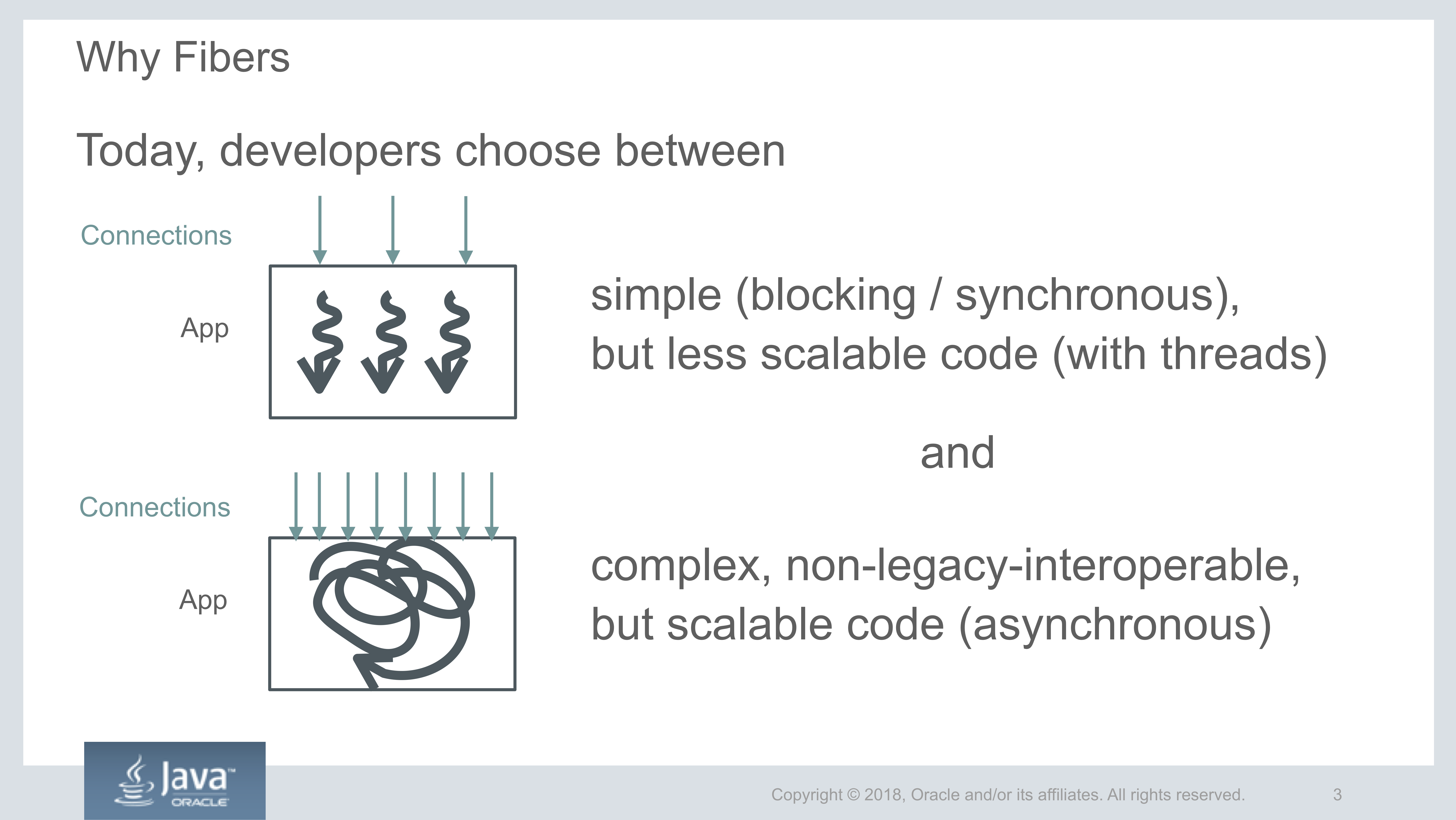
The following is a great image that depicts the choice that developers have to make today, between simple blocking / synchronous code (using threads) and complex but scalable (asynchronous) code.
Structured concurrency #
Loom implements structured concurrency in the JVM. The core concept of structured concurrency is that when control splits into concurrent tasks that they join up again. If a “main task” splits into several concurrent sub-tasks scheduled to be executed in fibers then those fibers must terminate before the main task can complete. This paper on nurseries explains the conceptual model behind doing concurrency in this way. This maps nicely when using Loom (using the Fork Join executor as the scheduler) or even Kotlin coroutines. Here are more links on this:
Overview #
- Here are the slides (PDF) of a 2018 video on Loom.
- This tutorial does a decent job comparing conventional use of BIO + threads to Fibers.
Fibers #
Fibers are lightweight, user-mode threads, scheduled by the Java virtual machine, not the operating system. Fibers are low footprint and have negligible task-switching overhead. You can have millions of them!
Continuation #
A Continuation (precisely: delimited continuation) is a program object representing a computation that may be suspended and resumed (also, possibly, cloned or even serialized).
Here’s an excerpt from the Continuation class:
package java.lang;
public class Continuation implements Runnable {
public Continuation(ContinuationScope scope, Runnable target);
public final void run();
public static void yield(ContinuationScope scope);
public boolean isDone();
}
In essence, most of us will never use Continuation in application code. Most of us will use Fibers to enhance our code. A simple definition would be:
Fiber = Continuation + Scheduler
- A fiber wraps a task in a continuation
- The continuation yields when the task needs to block
- The continuation is continued when the task is ready to continue
- Scheduler executes tasks on a pool of carrier threads
- java.util.concurrent.Executor in the current prototype
- Default/built-in scheduler is a ForkJoinPool
Backwards compatibility #
One of the challenges of any new approach is how compatible it will be with existing code. Project Loom team has done a great job on this front, and Fiber can take the Runnable interface. To be complete, note that Continuation also implements Runnable.
Non-blocking IO #
The Project Loom JDK has also reimplemented portions of the Java networking API to be non blocking and fiber friendly. Here’s more info on this.
Changes that need to be made to the BIO project #
The only part of our current server that will change is the thread scheduling part; the logic inside the thread remains the same.
Here’s the old school code using BIO + threads (written in Kotlin).
fun main() {
val server = ServerSocket(PORT)
while (true) {
// Blocking code.
val socket = server.accept()
connectionCount++
// Create a new thread and start it (does not block).
val socketHandlerThread = SocketHandlerThread(socket)
socketHandlerThread.start()
}
}
Here’s the Project Loom code using Fibers.
public static void main(String[] args) {
try {
ServerSocket server = new ServerSocket(10_000);
while (true) {
Socket client = server.accept();
EchoHandlerLoom handler = new EchoHandlerLoom(client);
FiberScope.background().schedule(handler);
}
} catch (Exception e) {}
}
For completeness, here’s the client side code (in Kotlin) which remains unchanged for both the old school example, and the one w/ Fibers.
const val THREAD_COUNT = 100_000
fun main() {
val elapsedTimeSec = measureTimeSec {
(1..THREAD_COUNT).forEach {
val thread = Thread { doWork(it) }
thread.start()
thread.join()
}
}
}
fun doWork(count: Int) {
val socket = Socket("localhost", PORT)
val inputStream = socket.getInputStream()
val reader = BufferedReader(InputStreamReader(inputStream))
val line = reader.readLine()
}
References #
Great baseline information related to JDK threading issues
- Excellent tutorial examining the differences, which sets up this project
- Why many threads can slow down programs
- IO vs NIO
- Java Servlet 3.0 going to async using NIO
Project Loom deep dive
Build Project Loom JDK
Fork Join Pool (scheduler for Loom’s lightweight threads)
OS thread scheduling and resource consumption
- Java thread scheduling
- OS thread scheduling and resources
- Preemption and sleep
- Multithreading cost, context switch, memory
- Context switching
Other examples that may be useful
👀 Watch Rust 🦀 live coding videos on our YouTube Channel.
📦 Install our useful Rust command line apps usingcargo install r3bl-cmdr(they are from the r3bl-open-core project):
- 🐱
giti: run interactive git commands with confidence in your terminal- 🦜
edi: edit Markdown with style in your terminalgiti in action
edi in action